算法中常见的数据结构
选用合适的数据结构是算法设计的重要一环,常见的数据结构有:数组、栈、队列、哈希表、链表、树、图、堆等。
这些数据结构都有各自的特点,甚至在某些场景下,它们之间还可以相互转换。比如,数组既可以用来顺序存储,也可以用来实现栈、队列和散列表。
数组
数组它是一种线性表数据结构,用一组连续的内存空间,来存储一组具有相同类型的数据。
数组的优点是支持随机访问,根据下标随机访问的时间复杂度是 O(1)。但是,数组也有缺点,比如,如果要在数组的头部或者中间插入一个元素,为了保证内存空间的连续性,就需要做大量的数据搬移工作,时间复杂度是 O(n)。
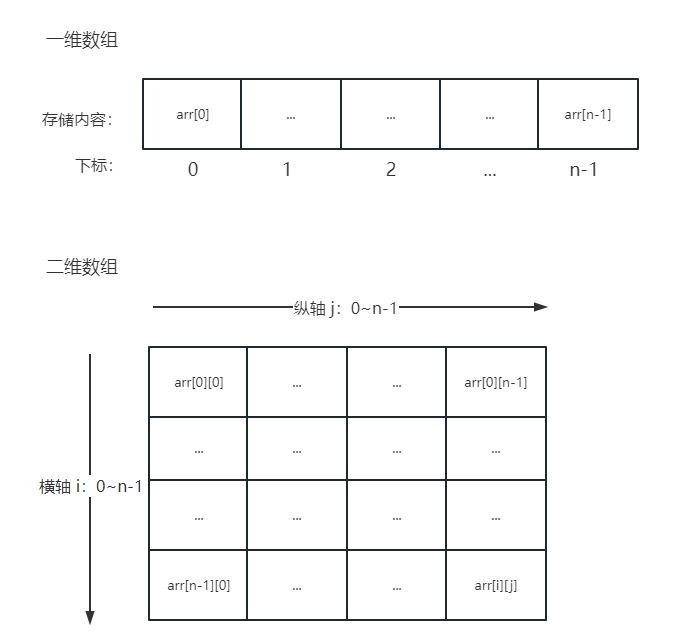
栈
栈是一种先进后出(First In Last Out)的数据结构,它只支持在一端插入和删除数据。
栈的应用场景有函数调用栈、括号匹配、表达式求值等。
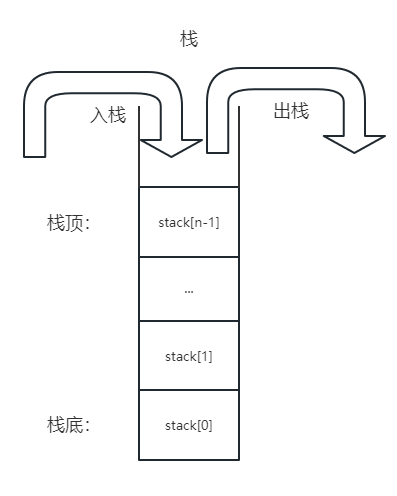
队列
队列是一种先进先出(First In First Out)的数据结构,它只支持在队尾插入数据,在队头删除数据。
队列的应用场景有广度优先搜索、缓存淘汰策略等。
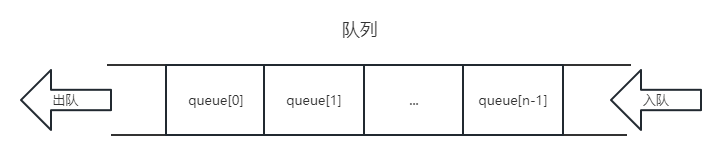
另外还有一种队列叫做双端队列(Deque),它支持在队头和队尾插入和删除数据。
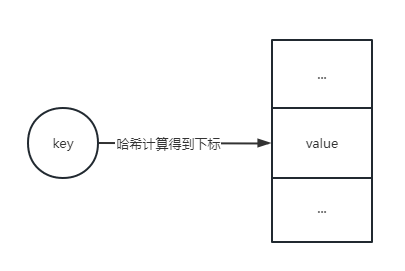
哈希表(散列表)
散列表是根据关键码值(Key Value)而直接进行访问的数据结构,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
散列表的应用场景有缓存、数据库索引等。优点是查找速度快,缺点是占用内存大,而且容易出现散列冲突。
散列冲突: 两个不同的关键码值经过散列函数计算得到的散列地址相同,这种现象称为散列冲突。
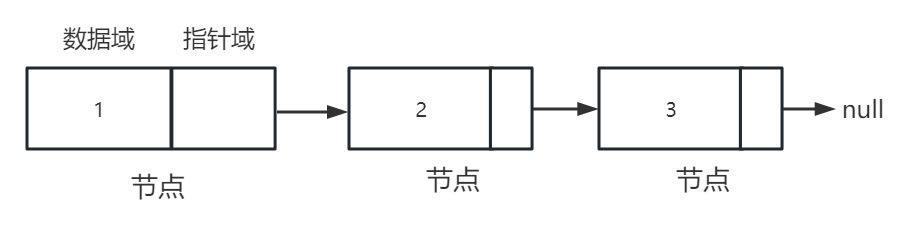
链表
链表是一种非连续的线性表数据结构,它通过指针将一组零散的内存块串联起来使用。
链表的优点是支持动态扩容,不需要像数组那样预先分配一块连续的内存空间。但是,链表也有缺点,比如,如果要随机访问链表中的某个元素,就需要从头开始遍历,时间复杂度是 O(n)。
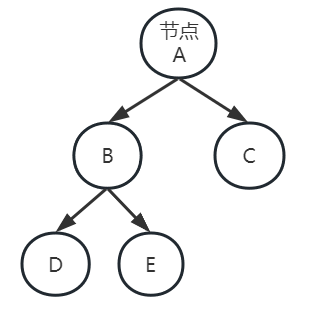
树
树是一种非线性的数据结构,它是由 n(n>=1) 个有限节点组成一个具有层次关系的集合。
树的节点包含两个基本部分:数据和指向子节点的指针。树的节点可以分为内部节点和外部节点。根节点是树的第一个节点,没有父节点的节点称为根节点。每个节点最多只能有一个父节点,但是可以有多个子节点。如果一个节点没有子节点,那么它就是叶子节点。
树的应用场景有二叉查找树、堆、Trie 树等。
图
图是一种非线性的数据结构,它由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G 表示一个图,V 是图 G 中顶点的集合,E 是图 G 中边的集合。
图的应用场景有最短路径算法、拓扑排序、求解关键路径等。
堆
堆是一种特殊的树形数据结构,它满足下列性质:
- 是一棵完全二叉树
- 树中的任意节点的值总是不大于(或不小于)其子节点的值
堆的应用场景有求 Top K 问题、求中位数等。
Contributors
 HearLing
HearLing